FAR.AI says it quickly found three jailbreaks in DeepSeek’s V4-Pro
The research group linked to a write-up and cited 98-100% figures after red-teaming DeepSeek’s latest model, according to a post amplified on X.
By Ryan Merket · Published
Why it matters
Independent red teams finding repeatable jailbreaks quickly suggests safety layers on popular models remain brittle. For founders, it is a reminder to budget for external adversarial evals and to ship defense-in-depth, not just prompt-level bandages.
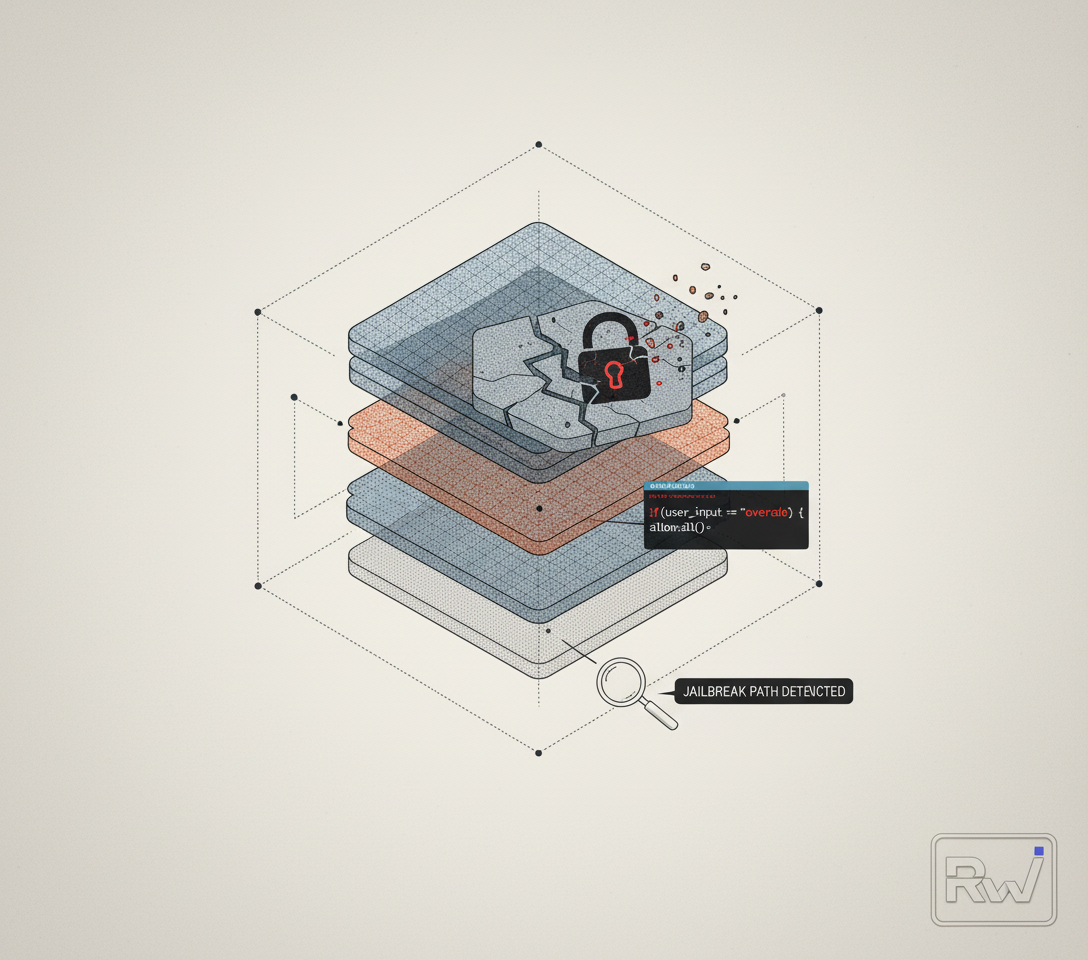
FAR.AI said it red-teamed DeepSeek’s V4-Pro and "almost immediately found three ways in," linking to a write-up on its site and citing 98-100% figures in its tests in a post on X that was amplified by Malcolm Murray (@malcmur). The post points to FAR.AI for more detail.
That is the core claim: multiple bypass paths and near-total success rates on the scenarios they tried. The X post does not include the full methodology inline. Readers are directed to FAR.AI’s site for the technical details behind the red team and the specific prompts or constraints involved.
What the team says they found
- Three distinct "ways in" that allowed V4-Pro to produce outputs it was presumably calibrated to avoid.
- 98-100% figures across their tests, as reported in the post.
We are not restating the exact categories of the tests (or the full definition of those figures) because they are not specified in the X post itself. The linked write-up is the authoritative source for those definitions and examples.
Why this lands for builders
If you are shipping or integrating LLMs, independent red teaming is the fastest way to surface failure modes that do not show up in happy-path evals. A small set of carefully crafted attack patterns often transfers across models and updates. When an external group can rapidly find multiple jailbreaks with high success rates, it typically means:
- Your guardrails are overfit to a narrow prompt and not the underlying intent.
- You lack defense-in-depth across input preprocessing, model-level refusals, and output filtering.
- Your evals may be measuring the wrong thing or using non-adversarial benchmarks.
Practical next steps
- Bring in an outside red team before and after launch to pressure-test your latest weights and safety layers.
- Define and publish your own adversarial success metrics so teams can track regressions when you patch.
- Invest in layered mitigations: prompt hardening, adversarial training where appropriate, and post-generation filters tuned to your risk surface.
- Treat jailbreak fixes as product work, not one-off patches. The goal is to reduce entire classes of exploits rather than whack-a-mole individual prompts.
What we do not know yet
- The full scope and methodology of FAR.AI’s tests, beyond the headline figures and claim of three paths.
- How DeepSeek will respond or whether patches are already in progress.
We will update this story if additional detail is published in FAR.AI’s linked write-up or if the model provider shares remediation steps.